Machine translation available:
Linked Open Data and Literary History
In a “Data-Rich Literary History” (Bode 2018a: 37), one can quantify literary phenomena like patterns in themes, narrative places, book formats, narrative forms, gender and more. Researchers in the field of Digital Humanities such as Franco Moretti (2013), Matthew Jockers (2013), Matt Erlin (2014), Katherine Bode (2018b), Ted Underwood 2019 or Nicholas Paige (2020) are transforming the way literary history is told in the sense of this paradigm. In our transdisciplinary project “Mining and Modelling Text”[1] at Trier University in Germany, we are following this approach and have extended it with ideas from the semantic web (Berners-Lee et al. 2006). We have extracted features relevant to literary history and modelled knowledge on French novels 1751-1800 in a multilingual knowledge base following the Linked Open Data paradigm (Schöch et al. 2022; Hinzmann et al. 2022a).
By using Digital Humanities methodology like Topic Modeling on full texts[2] (Klee / Röttgermann 2022) or information extraction from bibliographic records,[3] we can aggregate statements on thematic concepts, publication places or narrative forms in about 2000 novels and interpret patterns in the data (Röttgermann et al. 2022b). Our Knowledge Graph is designed to capture the complex relationships between works, thematic concepts, authors, locations and other relevant entities, and to provide both overview and detail throughout the graph.

Infrastructure
For the provision of data, we follow Open Science principles, such as the publication of FAIR data in open access as well as the use of open source software – in particular Wikibase (see fig. I).[4]
We created a custom bot (Steffes 2021) using the Python library Pywikibot to import and update RDF triples into our Wikibase instance from TSV files.
We extract and import triples from three different sources on French novels of the eighteenth century: primary texts (novels), bibliographic metadata and secondary literature (fig II). You can query and visualize all triples stored in our Wikibase instance through the DockerWikibase Query Service interface (Wikimedia Deutschland 2012).
All properties and controlled vocabularies are stored in three languages: French, German and English. Wikibase is particularly well-suited to store multilingual data as it has built-in support for language-specific labels, descriptions, and aliases, which make it easy to search for, retrieve or visualize data in a specific language.
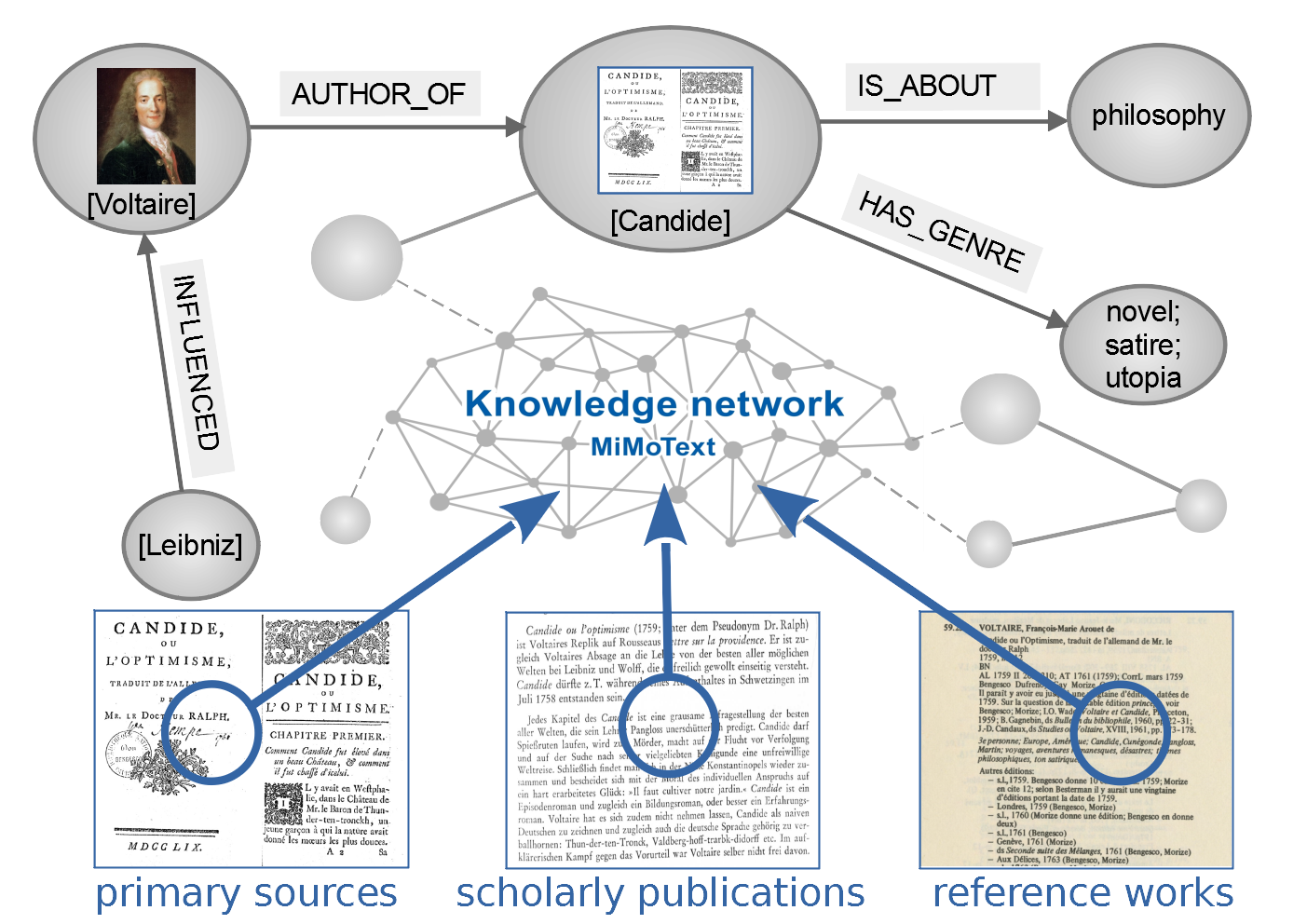
Methods
Using Computational Literary Studies (CLS) methods such as Topic Modelling, sentiment analysis, co-occurrence analysis or Named Entity Recognition (Röttgermann et al. 2022a), we extract statements from primary sources, scholarly publications and reference works.
The reference works themselves provide the entities (authors and works) of the overall literary production of French novels 1751-1800 and contain information on main characters, the narrative location, places of publication, the year of the first edition, main subjects, tonality of the novel, page counts, book format or publishing houses. In order to be able to compare themes and topics, tonalities and sentiments or narrative places extracted from different sources, we built several controlled vocabularies on common themes, narrative locations and narrative forms of French Novels in the Eighteenth Century (Klee / Hinzmann 2021). This allows us to compare statements originally formulated by humans with statements created using algorithmic information extraction.
Querying
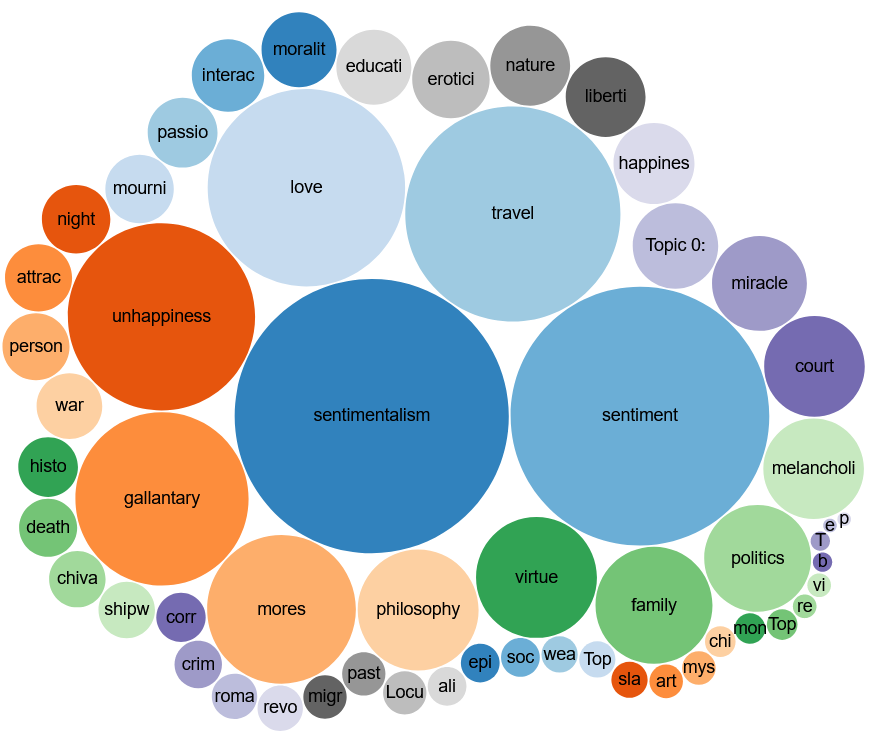
In order to test the utility of our Knowledge Graph, we have developed a number of use cases in which we demonstrate the value of this new approach (Hinzmann et al. 2022b). These use cases include visualizations and explorations of the graph, as well as more focused queries (using the SPARQL query syntax), focused on the identification of literary trends and the analysis of specific patterns in thematic concepts, narrative locations or publication places within the corpus. We can gain an overview of common themes of French prose 1751-1800 (see fig. III) or explore ‘federated queries’, where information from other knowledge bases (here Wikidata) can be integrated and by that means add more layers of information to the query, such as geo-coordinate data (see fig. V).
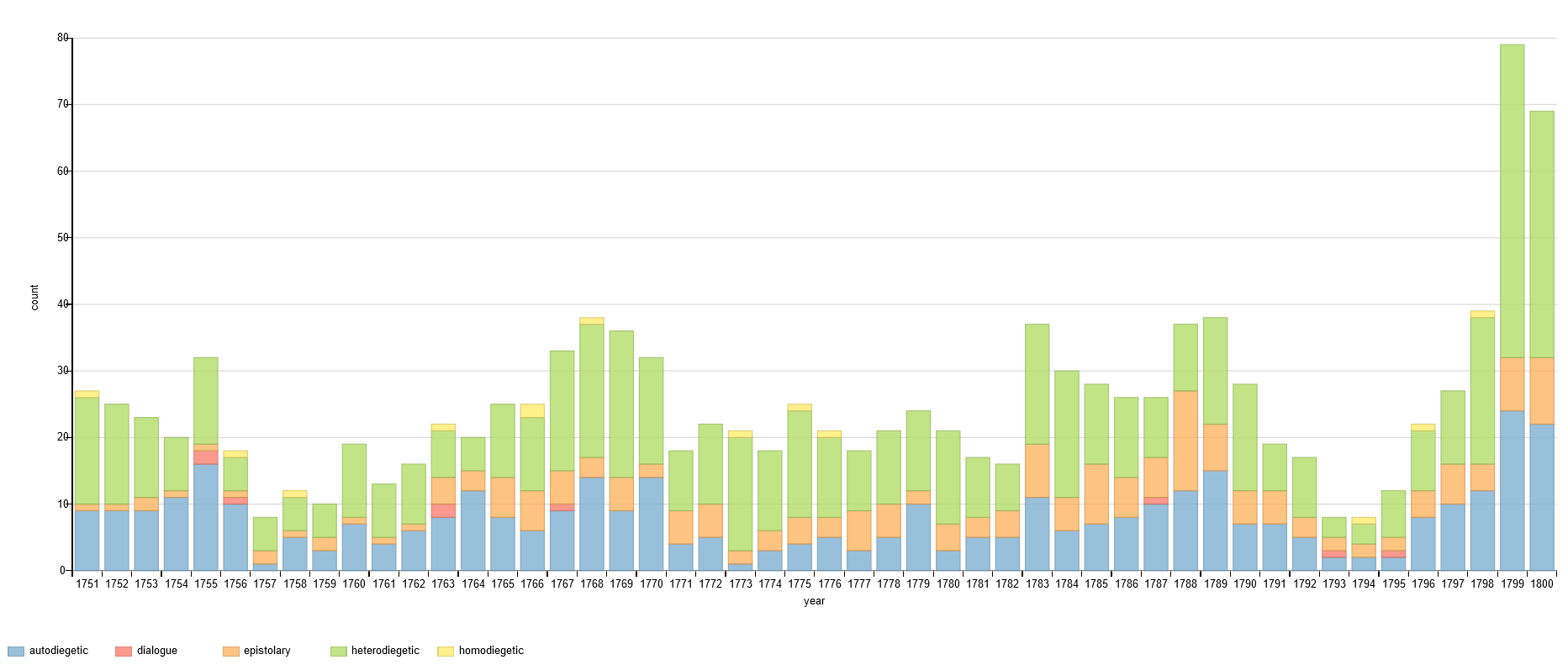
We can also query for narrative form in a diachronic perspective:
… or inspect publication places of French novels 1751-1800 with geo-coordinate data:
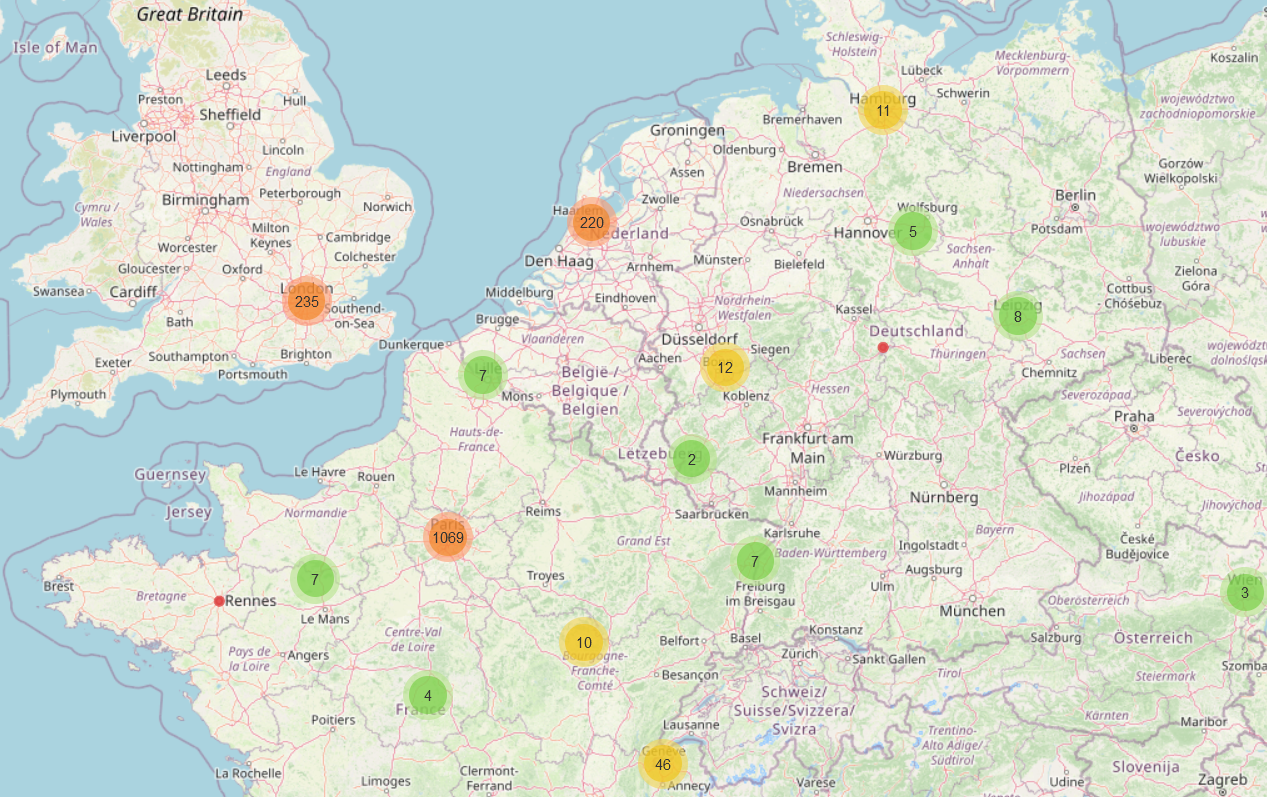
Our knowledge base gives data-driven insights on French Enlightenment authors, varying book formats, patterns of themes and topics and shifts in the production of novels (for example sudden changes in patterns concerning the places of publication).
Overall, we believe that the development of a multilingual Knowledge Graph for 18th Century French literature fed from diverse sources and modelled as Linked Open Data has the potential to open up new directions for a datafied view on literary history, as it enables researchers to ask new types of questions and generate new insights into a critical period in French literary history.
***
If you want to gain insights on the knowledge base built within our project, discover more use cases or learn SPARQL to write your own queries, we invite you to have a look at our tutorial: www.docs.mimotext.uni-trier.de.
***
![]()
The research in “Mining and Modelling Text” (University of Trier) is funded by the “Forschungsinitiative Rheinland-Pfalz” 2019-2023.
By Julia Röttgermann (Trier Center for Digital Humanities). All work in MiMoText is team work: Christof Schöch, Maria Hinzmann, Tinghui Duan, Anne Klee, Johanna Konstanciak.
[1] See the project website: https://www.mimotext.uni-trier.de/en.
[2] For the corpus of full texts see Röttgermann et al., 2023.
[3] Bibliographic metadata on French novels 1751-1800 can be found in Martin / Mylne / Frautschi 1977; Lüschow 2019.
[4] Generally, see Suber 2012 and Wilkinson et al. 2016; related to the project, see Röttgermann / Schöch 2020 and Schöch 2021. Link to our Wikibase instance: www.data.mimotext.uni-trier.de.
References
Berners-Lee, Tim / Weitzner, Daniel J. / Hall, Wendy / O’Hara, Kieron / Shadbolt, Nigel / Hendler, James A. (2006): “A Framework for Web Science”, in: Foundations and Trends in Web Science 1 (1): 1–130. 10.1561/1800000001.
Bode, Katherine (2018a): “Back to the Future:A New Scholarly Object for (Data-Rich) Literary History” in: A World of Fiction: Digital Collections and the Future of Literary History. Illustrated Edition University of Michigan Press 37–58.
Bode, Katherine (2018b): A World of Fiction: Digital Collections and the Future of Literary History. Illustrated Edition University of Michigan Press.
Erlin, Matt (2014): “The Location of Literary History: Topic Modeling, Network Analysis, and the German Novel, 1731–1864” in: Distant Readings: Topologies of German Culture in the Long Nineteenth Century. NED-New edition Boydell & Brewer 55–90.
Hinzmann, Maria / Klee, Anne / Konstanciak, Johanna / Röttgermann, Julia / Schöch, Christof / Steffes, Moritz (2022a): MiMoTextBase. https://data.mimotext.uni-trier.de [letzter Zugriff 1. August 2022].
Hinzmann, Maria / Klee, Anne / Konstanciak, Johanna / Röttgermann, Julia / Schöch, Christof / Steffes, Moritz (2022b): MiMoTextBase Tutorial. https://mimotext.github.io/MiMoTextBase_Tutorial/ [letzter Zugriff 1. August 2022].
Jockers, Matthew L. (2013): Macroanalysis: Digital Methods and Literary History. University of Illinois Press.
Klee, Anne / Hinzmann, Maria (2021): MiMoText/vocabularies. Mining and Modeling Text (MiMoText). https://github.com/MiMoText/vocabularies/blob/65acb008838fc13044aac554e05b3c2bbccbd12f/Themenvokabular.tsv [letzter Zugriff 2. Juli 2021].
Klee, Anne / Röttgermann, Julia (2022): ““Nuit, correspondance, sentiment” – Topic Modeling auf einem Korpus von französischen Romanen 1750-1800”, in: apropos: Perspectives on Romania Romanistentag 2021, Sektion Digital, global, transdisziplinär: Impulse für eine transdisziplinäre digitale Romanistik. (9): 57–86. https://doi.org/10.15460/apropos.9.1888.
Lüschow, Andreas (2019): Bibliographie du genre romanesque français, 1751-1800: RDF model [Data set]. Trier: Trier University. http://doi.org/10.5281/zenodo.3401428.
Martin, Angus / Mylne, Vivienne / Frautschi, Richard L. (1977): Bibliographie du genre romanesque français, 1751-1800. London: Mansell.
Moretti, Franco (2013): Distant reading. London ; New York: Verso.
Paige, Nicholas D. (2020): Technologies of the Novel: Quantitative Data and the Evolution of Literary Systems. New York: Cambridge University Press.
Röttgermann, Julia (ed. ) Dudar, Julia / Gebhard, Henning / Klee, Anne / Konstanciak, Johanna / Padieu, Damir /Probst, Amelie /Ondraszek, Sarah Rebecca /Schöch, Christof (2023): “Collection de romans français du dix-huitième siècle (1751-1800) / Eighteenth-Century French Novels (1751-1800) [dataset]”, in: Release v0.3.0: 10.5281/zenodo.7712928.
Röttgermann, Julia / Hinzmann, Maria / Gebhard, Henning / Klee, Anne / Konstanciak, Johanna / Schöch, Christof / Steffes, Moritz (2022a): Mining and Modeling Spaces and Places for Literary History as Linked Open Data. in: Ohmukai, Ikki / Yamada, Taizo (eds.): DH 2022 – Conference Abstracts. Tokyo: DH2022 Local Organizing Committee. https://zenodo.org/record/6948236 [letzter Zugriff 1. August 2022].
Röttgermann, Julia / Klee, Anne / Hinzmann, Maria / Schöch, Christof (2022b): Literaturgeschichtsschreibung datenbasiert und wikifiziert?. in: Geierhos, Michaela / Trilcke, Peer / Börner, Ingo / Seifert, Sabine / Busch, Anna / Helling, Patrick (eds.): DHd2022: Kulturen des digitalen Gedächtnisses. Konferenzabstracts. Potsdam. https://zenodo.org/record/6328157#.YnIbrpZCRhE.
Röttgermann, Julia / Schöch, Christof (2020): FAIRe Daten in den Literaturwissenschaften? Das Beispiel „Mining and Modeling Text“ und der französische Roman des 18. Jahrhunderts. in: Romanistik-Blog. Blog des Fachinformationsdienstes. https://blog.fid-romanistik.de/2020/11/05/faire-daten-in-den-literaturwissenschaften/.
Schöch, Christof (2021): “Open Access für die Maschinen” in: Effinger, Maria / Kohle, Hubertus (eds.): Die Zukunft des kunsthistorischen Publizierens. arthistoricum.net 79–94. 10.11588/ARTHISTORICUM.663.
Schöch, Christof / Hinzmann, Maria / Röttgermann, Julia / Klee, Anne / Dietz, Katharina (2022): “Smart Modelling for Literary History”, in: IJHAC: International Journal of Humanities and Arts Computing [Special issue on Linked Open Data] 16 (1): 78–93. https://doi.org/10.3366/ijhac.2022.0278.
Schöch, Christof / Jannidis, Fotis (2013): Quantitative Text Analysis for Literary History – Report on a DARIAH-DE Expert Workshop. Göttingen: DARIAH-DE. 13. (= DARIAH-DE Working Papers). http://webdoc.sub.gwdg.de/pub/mon/dariah-de/dwp-2013-2.pdf.
Steffes, Moritz (2021): MiMoText/Wikibase-Bot. https://github.com/MiMoText/Wikibase-Bot [letzter Zugriff 20. Dezember 2022].
Suber, Peter (2012): Open Access. Cambridge, Mass: The MIT Press.
Underwood, Ted (2019): Distant horizons: digital evidence and literary change. Chicago: The University of Chicago Press.
Wikimedia Deutschland (2012): Wikibase. Wikimedia Foundation. https://wikiba.se/ [letzter Zugriff 27. April 2022].
Wilkinson, Mark D. et al. (2016): “The FAIR Guiding Principles for scientific data management and stewardship”, in: Scientific Data 3 (1): 160018. 10.1038/sdata.2016.18.